Automatic Semblance Picking using Clustering Algorithms
by Yuqing Chen
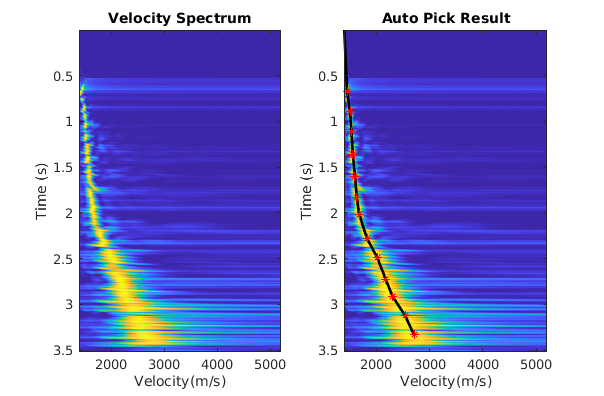
In this lab, we use the K-means clustering method to automatically pick the velocity spectrum.
Automatic picking paper autosembpick.pdf
-
Matlab
- Set the number of clusters as K.
- Place K points into space which represent the initial centroid of each cluster.
- Assign each data points to the cluster that has the closest centroid.
- After all points have been assigned, re-compute the centroid of each cluster.
-
Repeat step 3-4 until convergence has been reached.
Download the codes K_Means_Method.zip and unzip it. Change your Matlab working directory under this file so you may able to use all necessary sub-functions. The main function is K_mean_cluster.m, open it in the Matlab script and run. The comments in the program will help you understand the Lab.
Let x = {x(i)}, i = 1, 2, ..., Nbe the set of N-dimensional feature vectors to be clustered into a set of K clusters, with the centroid points at C. The misfit function is defined as
ϵ = (1)/(2)K⎲⎳i = 1(1)/(mi)mi⎲⎳j = 1∥ Ci − xij∥2,
where K is the number of clusters and miindicate the number of data points in the ithcluster. These cluster centroids can be iteratively updated by
C(k + 1)i = C(k)i − (1)/(m(k)i)m(k)i⎲⎳j = 1( C(k)i − x(k)ij),
C(k + 1)i = (1)/(m(k)i)mki⎲⎳j = 1 x(k)ij.
where the updated centroid C(k + 1)i is actually the averaged result of the data points in the ith cluster.
- comment the “thresholding” procedure in the program and re-run the program. How is the K-means method performs and why?
-
How to choose the number of clusters?
Please let me know if there are any errors in this Lab, please contact: yuqing.chen@kaust.edu.sa
Regards,
Yuqing Chen